近日国内DeepSeek V3大模型表现优异,且价格非常的便宜。结合Langchain做了本地知识库的问答。
使用的是Api的方式,并非本地搭建部署大模型。
项目是一个AI驱动的知识库助手,旨在帮助用户从PDF文档中获取信息并进行对话。下面是整体实现的一个架构图。
graph TD
A[开始] --> B[文档处理]
B --> B1[文档加载<br>LangChain Loader]
B --> B2[文本分块<br>TextSplitter]
B1 --> C[Embedding处理]
B2 --> C
C --> C1[选择Embedding模型<br>HuggingFace]
C --> C2[批量向量化处理]
C1 --> D[向量数据库]
C2 --> D
D --> D1[数据库选择<br>Chroma]
D --> D2[向量索引与存储]
D1 --> E[问答实现]
D2 --> E
E --> E1[向量相似度检索]
E1 --> E2[获取相关文档]
E2 --> E3[LLM答案生成]
classDef process fill:#f9f,stroke:#333,stroke-width:2px;
classDef database fill:#bfb,stroke:#333,stroke-width:2px;
classDef endpoint fill:#fbb,stroke:#333,stroke-width:2px;
class B,C process;
class D database;
class A endpoint;系统架构
项目包含四个核心模块:
- 语言模型 (ChatOpenAI):负责理解和生成自然语言
- 知识库:存储和管理文档信息
- 对话管理:处理问答匹配和上下文维护
- 用户接口:提供命令行交互
技术实现
- 文档处理:解析文档并分块存储
- 向量检索:将文本转换为向量进行相似度搜索
- 对话交互:支持多轮对话,保持上下文连贯
- 用户体验:提供加载动画和打字机效果的反馈
一个产品的mvp,我还是喜欢用CLI或者现有的成熟框架(例如:Streamlit等),这样可以快速的验证。
在小红书上放了3天,有几百人过来询问,所以打算把这个项目的代码分享出来。
运行起来需要用到deepseek v3(官网:https://platform.deepseek.com/)的api key,价格很便宜,买10块钱的就可以用,然后再如下文件填写key
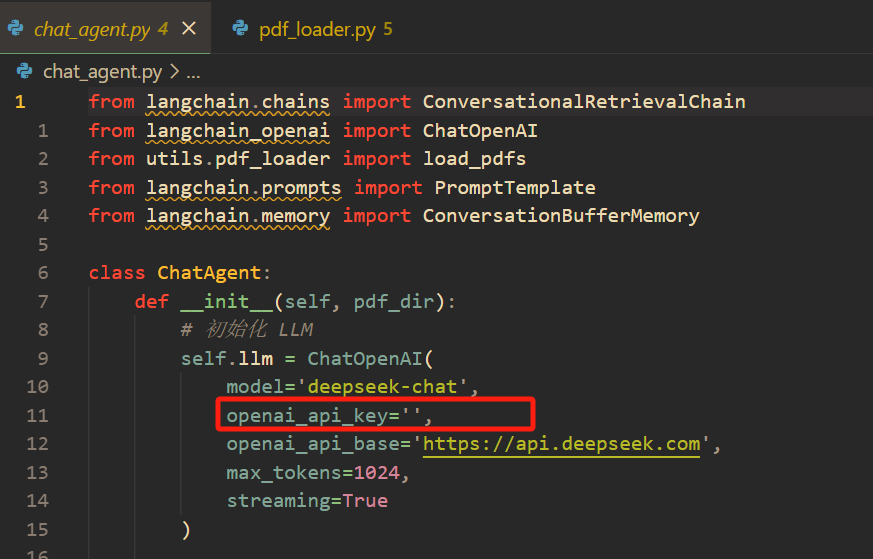
本次只支持pdf版本,后续会把主流的企业文档(word、excel、txt、html、ppt等)考虑整合进去。
如果个性化开发,可以微信我哈

文章评论